Beyond Benchmarks: Building Evals That Reflect Reality
When building systems with non-deterministic outputs -like language models -evaluation mechanisms become critical. Evals are how we keep ourselves honest -they tell us whether our AI feature is actually doing what we think it is.
Two core obstacles complicate evaluation design:
- Defining accuracy for your specific use case
- Creating ground truth data reflecting real-world production complexity
Teams often default to convenient automated benchmarks rather than designing task-appropriate evaluations, creating dangerous gaps between measured performance and actual user impact.
Why Benchmarks Can Be Misleading
Consider a concrete case study comparing Claude Sonnet 4.5 performance across contexts. While the model achieved 89.1% accuracy on MMLU and significantly outperformed earlier versions on industry benchmarks, it performed poorly on Multitudes' internal Feedback Quality evaluation -demonstrating that generic benchmarks don't tell you whether a model works for your task.
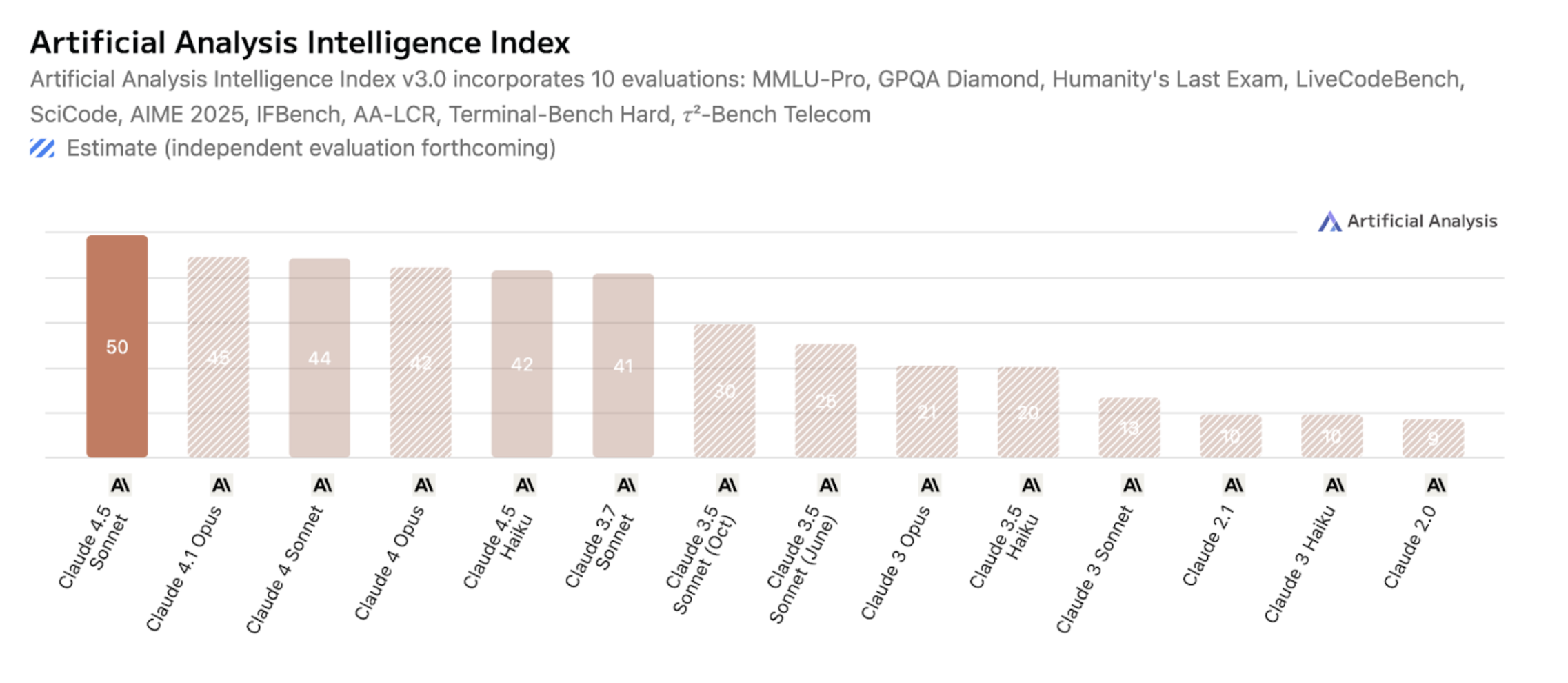
Artificial Analysis Intelligence Index shows evaluations comparing Claude 4.5 Sonnet highest.
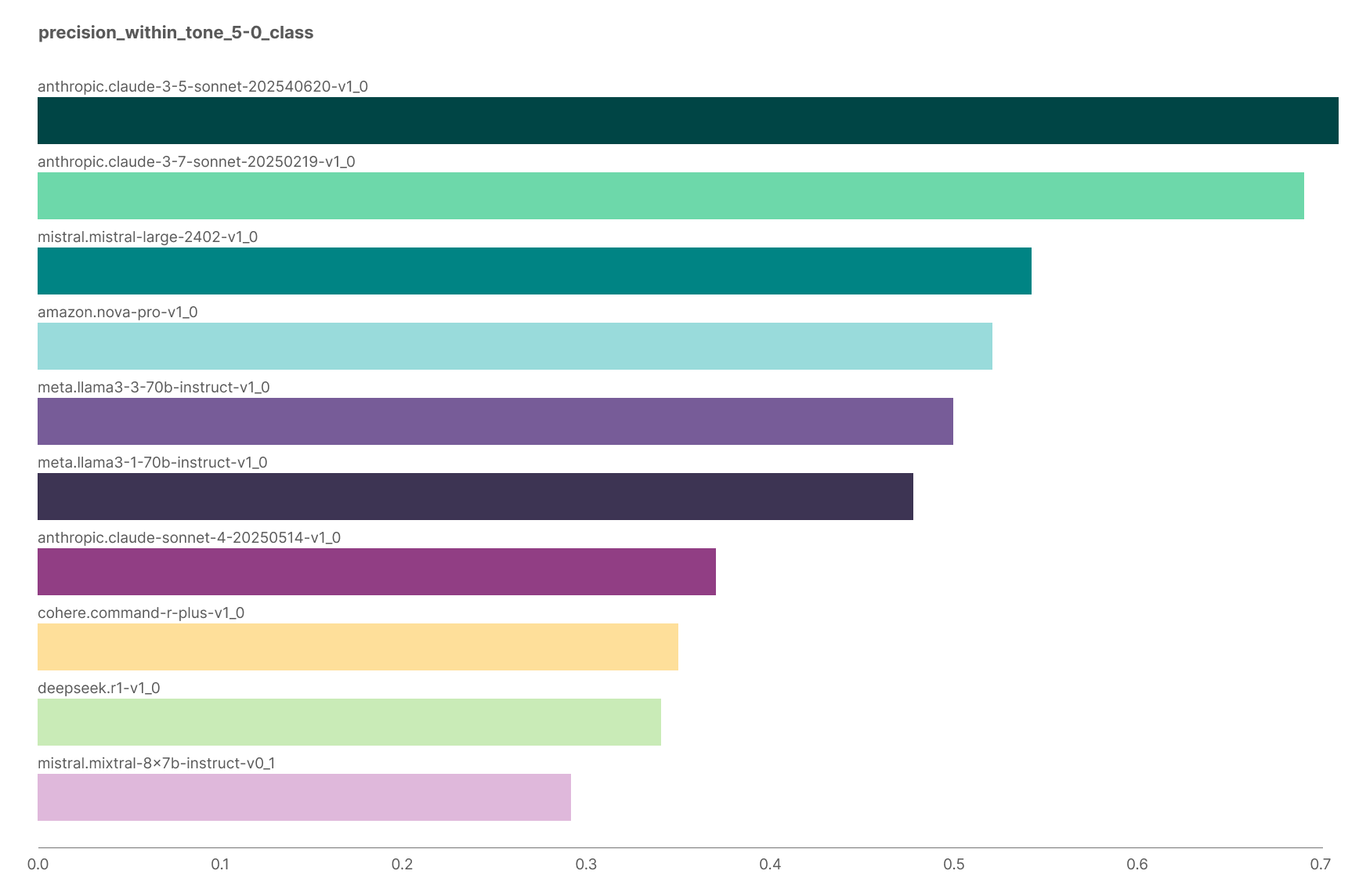
Chart showing Claude 3.5 Sonnet with highest precision on internal evals.
This pattern illustrates the "no free lunch theorem," establishing that no algorithm universally solves all problems. Recent research found that 284 benchmarks often suffer from data leakage and cultural bias, with models optimising for benchmark characteristics rather than genuine capability gains.
The key reframing: stop asking "what's the best model?" Start asking "what characteristics define my problem?"
Designing Evals That Matter
Why Evals Deserve Investment
Poor evaluation compounds downstream decisions. The Gender Shades project exemplified this: IBM, Microsoft, and Face++ reported 90%+ accuracy while exhibiting 34.7% error rates for darker-skinned women. Their evaluations lacked granular segmentation, testing on demographically unrepresentative datasets.
Two Foundational Elements
- Ground truth data genuinely representing your problem
- Evaluation metrics measuring what matters to users
Building Ground Truth Data
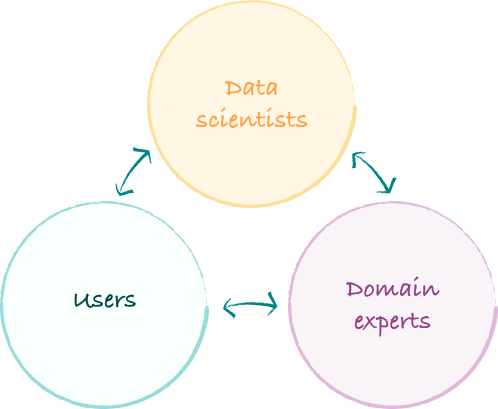
Getting Alignment
Three groups must align -often speaking different languages:
- Users experience problems but struggle articulating them
- Domain experts understand subtle contextual nuances
- Data scientists translate human judgment into structured metrics
For Feedback Quality evaluation, the team spent considerable time debating what "negative" feedback meant -considering terseness, cultural communication differences, and delivery context.
Alignment Process
The approach involved:
- Motivating the labeling team on feature importance
- Sharing contextual literature and examples
- Having all labelers annotate an initial shared dataset
- Reviewing mismatches and refining guidelines
Inter-rater reliability (IRR) metrics like Cohen's kappa or Krippendorff's alpha reveal whether definitions are sufficiently precise. Low IRR signals ambiguous categories needing clarification, not simply more data collection.
Reflecting Reality

Ground truth must mirror actual users and scenarios using appropriate sampling techniques. The labeling interface should restrict annotators to information available to the model -preventing bias from additional context humans see but models cannot access.
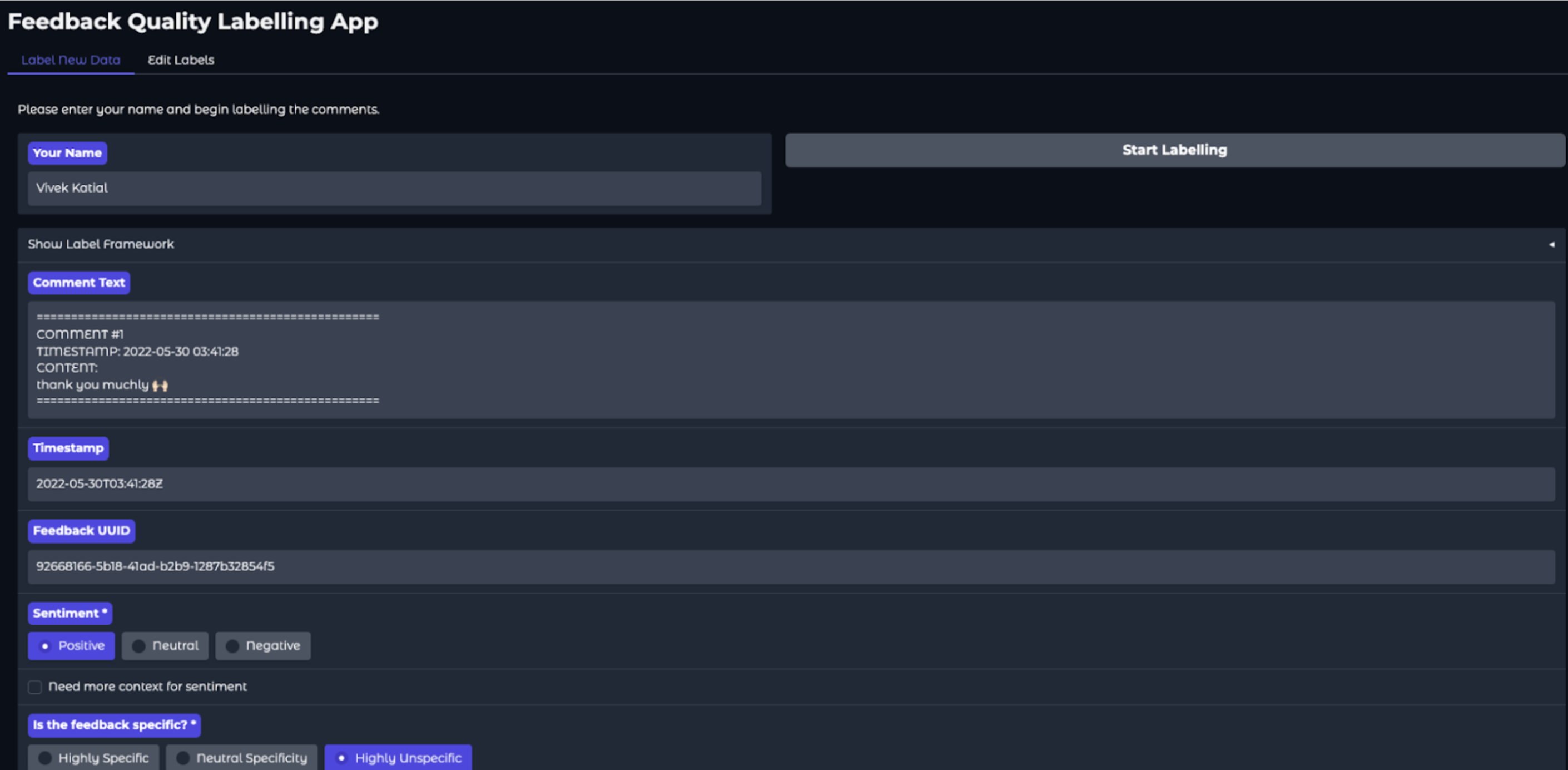
Feedback Quality Labelling App
The team observed gender differences in labeling: women were more likely to identify feedback as negative. These patterns matched broader user base observations, demonstrating that diverse labeling teams surface important nuances.
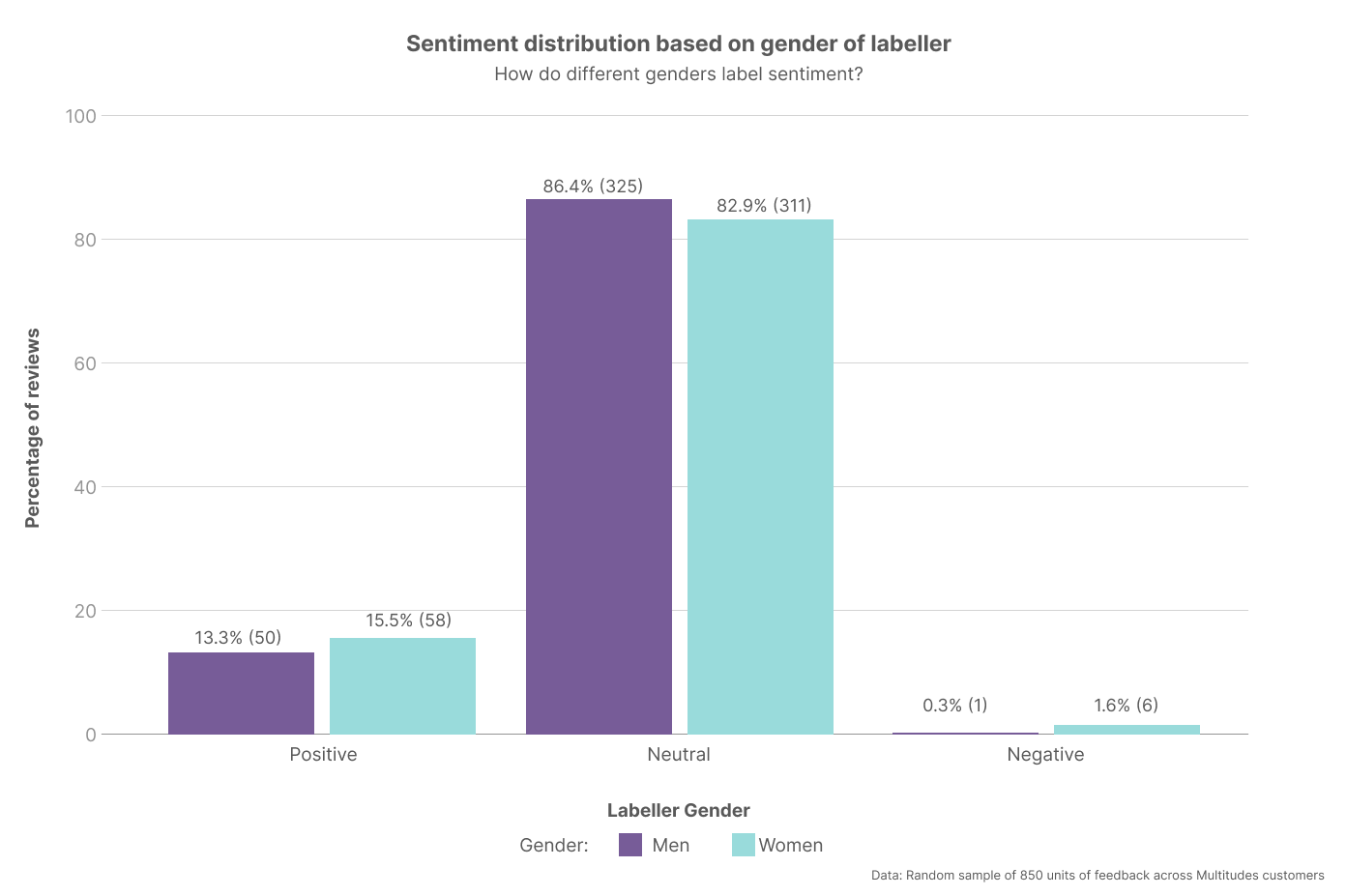
Sentiment distribution based on gender showed both leaned neutral but women were more likely to identify feedback as negative.
Choosing Metrics That Matter
Not all classification errors carry equal weight. When building Feedback Themes, the team recognised that confusing similar subcategories (like "Code Readability" vs. "Code Formatting") differs substantially from cross-category errors (misclassifying "Security" as "Communication").
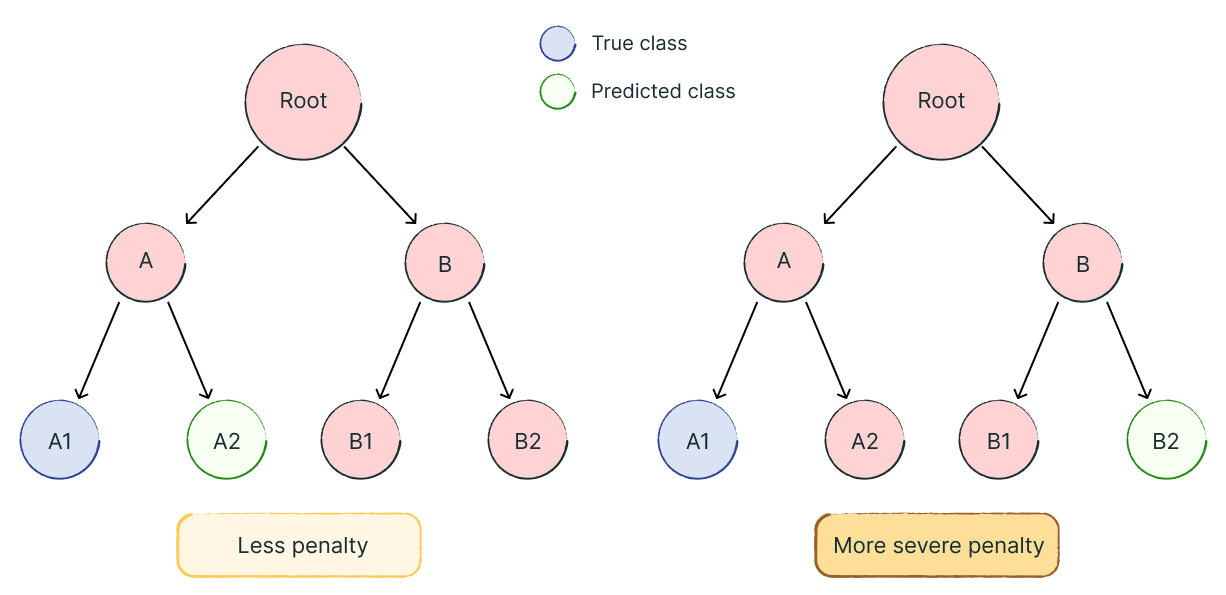
More severe penalties for classification errors further apart from each other.
They implemented Wu-Palmer similarity, measuring semantic distance within hierarchical taxonomies -reflecting that some prediction errors are less consequential than others.
Metric Selection Principles
- Connect metrics directly to user experience rather than standard ML measures
- Weight different error types according to actual impact
- Examine performance across data segments, not just aggregate accuracy
Aggregate metrics hide failures affecting specific populations.
Tools Supporting Evaluation
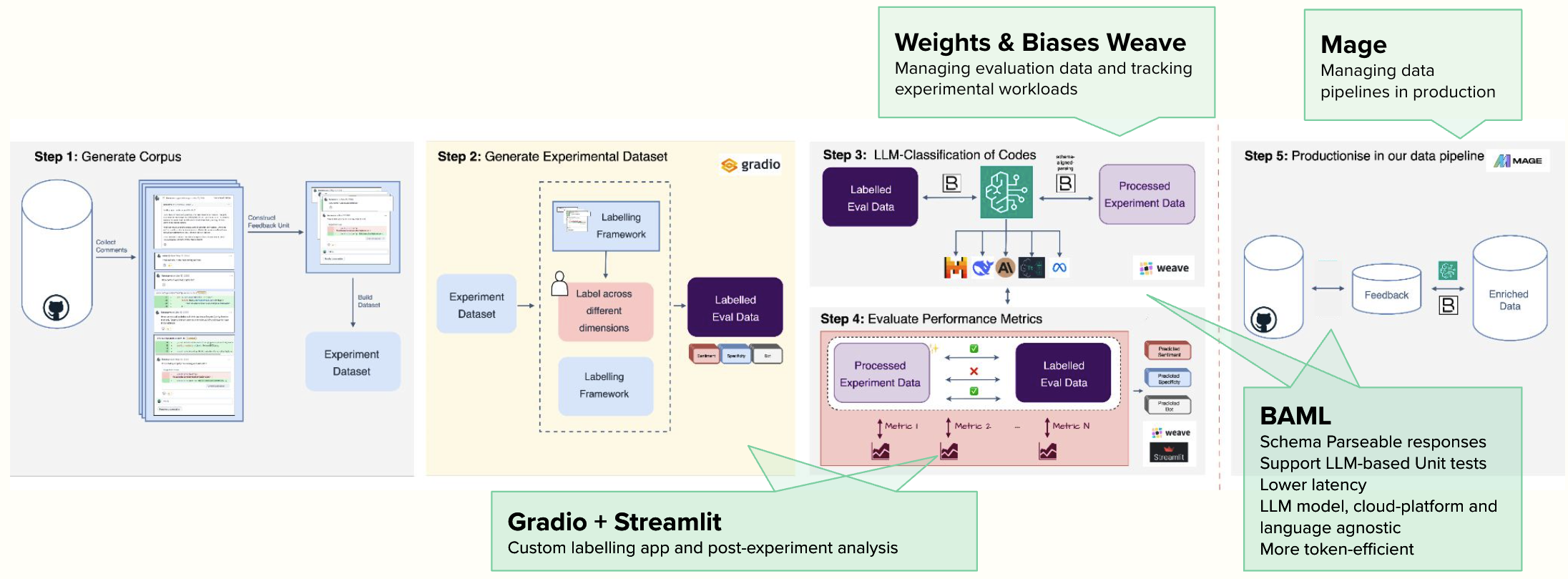
BAML provides schema-validated, strongly-typed LLM responses with built-in testing capabilities, enabling quick prompt iteration.
Weights & Biases Weave systematically tracks datasets, experimental parameters, and metrics while sharing results with stakeholders.
Gradio and Streamlit facilitated custom labeling interfaces and post-experiment analysis.
Mage orchestrated production workflows for data transformation and prediction.
The key principle: leverage existing tools rather than building infrastructure, reserving effort for rigorous evaluation design.
Key Takeaways
Evaluation rigor directly impacts production quality. Building trustworthy evals requires:
- Ground truth datasets with domain experts labeling real use-case examples
- Metrics connected to actual user experience rather than standard benchmarks
- Performance assessment across diverse population segments
- Iterative refinement where systems genuinely fail
Ultimately, the relevant question isn't benchmark accuracy -it's whether the system meaningfully improves users' experiences.