Data Ethics & Mitigating Algorithmic Bias

This is the website version of an article I originally wrote for the Multitudes blog, and later adapted for the Good Data Institute with a not-for-profit focus.
Algorithms now pervasively influence access to information and resource allocation. While technology offers substantial benefits, it can simultaneously perpetuate systemic oppression and bias. At Multitudes we collect sensitive behavioural data, making robust ethical principles essential. This article explores the machine learning lifecycle, how biases emerge throughout development, mitigation strategies, and implementation approaches.
What Does Algorithmic Bias Actually Mean?

Harmful impacts of algorithmic bias gaining headlines in the press.
Algorithmic bias describes systems that "systematically and repeatedly produce outcomes that benefit one particular group over another."
When neural networks trained on ImageNet analysed wedding photographs, Western brides received labels like "bride" and "wedding," while Indian brides received "costume" and "performing arts." This disparity reflects dataset limitations -popular image datasets contain predominantly European and North American imagery despite Asia containing the majority of global population.
The Machine Learning Lifecycle
The five stages of the machine learning lifecycle.
The ML development process comprises five stages where biases can emerge:
- Data Collection and Preparation
- Feature Engineering and Selection
- Model Evaluation
- Model Interpretation and Explainability
- Model Deployment
Stage 1: Data Collection and Preparation

Process: Collecting, labelling, and preparing data for modelling purposes.
How Bias Arises: Datasets often don't reflect reality. Popular image datasets contain images mostly from Europe and North America, creating geographic representation gaps that degrade model performance for Asian and African populations.
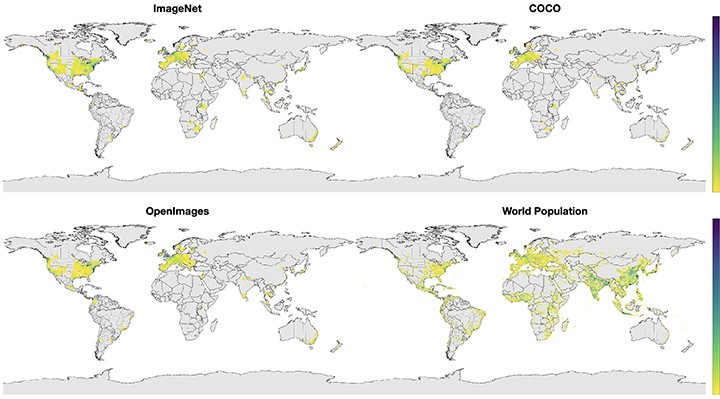
Geographical distribution of images in popular datasets compared to world population density.
Mitigation Strategy: Ensure data collection reflects reality. Consider oversampling data from marginalised groups to create equitable datasets. Timnit Gebru's "Datasheets for Datasets" provides a framework for transparent, accountable data collection.
Stage 2: Feature Engineering and Selection

Process: Constructing characteristics (features) that help predict outcomes.
How Bias Arises: Even removing obviously sensitive features like race or gender doesn't eliminate bias. Proxy variables like postal codes correlate with demographic characteristics. Predictive policing systems can propagate and exacerbate racial biases by relying on biased historical data.
Mitigation Strategy: Critically examine feature relationships and their demographic correlations. Engage diverse communities and stakeholders participatorily. Community-Based System Dynamics approaches help design fairer systems by involving affected groups.
Stage 3: Model Evaluation

Process: Assessing model accuracy for predicting outcomes.
How Bias Arises: Evaluating models using aggregate metrics masks disparities across demographic groups. The Gender Shades Project revealed that while facial recognition systems claimed 90% accuracy, error rates for darker-skinned women reached 34.7% versus 0.8% for lighter-skinned men.
Mitigation Strategy: Advocate for intersectional performance measures broken down by demographic subgroups. Use model cards documenting accuracy across diverse populations.
Stage 4: Model Interpretation and Explainability

Process: Understanding how and why models produce specific results.
How Bias Arises: Opaque algorithms can unfairly harm individuals. A Washington DC teacher faced termination based on an algorithm ranking her in the bottom 2% despite excellent student and parent reviews.
Mitigation Strategy: Ensure transparency about how personal data is used. Teams should understand ML systems they build. Data scientists can employ tools like SHAP and LIME to interpret model behaviour and feature importance.
Stage 5: Model Deployment

Process: Moving trained models into production environments.
How Bias Arises: Models may be misapplied beyond original purposes. Microsoft's NLP chatbot learned racial slurs within 24 hours on Twitter. Concept drift -distribution changes in production data -degrades performance for certain demographics.
Mitigation Strategy: Consistently track input data quality. Monitor whether production data distributions match training data. Version, label, and date models for easy rollback when performance deteriorates.
How We Implemented These Principles at Multitudes
Data Collection
- Follow reciprocity principles -only collect data from people who benefit from it
- Share data with both managers and team members
- Distribute labelling across diverse people to minimise labelled-data bias
Feature Engineering
- Avoid demographic features when analysing feedback quality
- Prevent penalising certain groups through proxy variables
Model Evaluation
- Conduct intersectional evaluation across team demographics
- Examine accuracy across different demographic subgroups before deployment
Model Deployment
- Execute "bad actor exercises" identifying malicious system uses
- Establish high accuracy thresholds protecting marginalised groups
Organisational Culture
- Reduce recruitment bias through proactive outreach
- Create environments amplifying underrepresented voices
- Provide individual allyship action plans
- Dedicate quarterly time to anti-racism and DEI workshops
Conclusion
Algorithmic bias emerges throughout ML development. While technical mitigations exist, addressing systemic oppression requires broader societal action through consumption choices, workplace practices, and civic participation.
Resources
Research Organisations
- Algorithmic Justice League
- Centre for AI and Digital Ethics
- Institute of Ethical AI and Machine Learning
- Human Rights Data Analysis Group
Tools & Frameworks
- Datasheets for Datasets
- DebiasWe (debiasing word embeddings)
- ACLU Algorithmic Equity Toolkit
- University of Michigan Data Ethics MOOC
Recommended Books
- Automating Inequality by Virginia Eubanks
- Weapons of Math Destruction by Cathy O'Neil
- Algorithms of Oppression by Safiya Umoja Noble
- Data Feminism by Catherine D'Ignazio & Lauren Klein